attn = MultiheadSelfAttention1D(nc=32, nh=4)Attention and Conditionality
In this module, we implement attention and conditionality
Adapted from
Attention is a “high-pass” filter that can help with the limitations of a “low-pass” filter such as a convolution.
Huggingface diffusers implements a 1D-attention by rasterizing the image, which is how we will implement this (although this is known to be “suboptimal,” accourding to Howard.) Then, each pixel has a \(C\)-dimensional embedding.
Johno mentions that softmax tends to assign all weight to a single dimension, but this is often undesirable. Multi-headedness compensates for this by creating many orthoganol subspaces within which attention is assigned.
See jer.fish/posts/notes-on-self-attention for more details.
MultiheadSelfAttention1D
def MultiheadSelfAttention1D(
nc, nh
):
Multi-head self-attention
x = torch.randn(8, 32, 16, 16)
attn(x).shapetorch.Size([8, 32, 16, 16])Let’s use this in a Diffusion UNet. Note that we cannot use attention near the beginning or head due to the quadratic time and space capacity (there are more time steps at these points). Typically, attention is only used when the feature map is 16x16 or 32x32 or higher.
TAResBlock
def TAResBlock(
t_embed, c_in, c_out, ks:int=3, stride:int=2, nh:NoneType=None
):
Res-block with attention
TADownblock
def TADownblock(
t_embed, c_in, c_out, downsample:bool=True, n_layers:int=1, nh:NoneType=None
):
Resdownblock with attention
TAUpblock
def TAUpblock(
t_embed, c_in, c_out, upsample:bool=True, n_layers:int=1, nh:NoneType=None
):
Resupblock with attention
TAUnet
def TAUnet(
nfs:tuple=(224, 448, 672, 896), attention_heads:tuple=(0, 8, 8, 8), n_blocks:tuple=(3, 2, 2, 1, 1),
color_channels:int=3
):
U-net with attention up/down-blocks
dls = get_fashion_dls(512)un = train(
TAUnet(
color_channels=1,
nfs=(32, 64, 128, 256, 384),
n_blocks=(3, 2, 1, 1, 1, 1),
attention_heads=(0, 8, 8, 8, 8, 8),
),
dls,
lr=1e-3,
n_epochs=25,
)| loss | epoch | train |
|---|---|---|
| 0.282 | 0 | train |
| 0.114 | 0 | eval |
| 0.084 | 1 | train |
| 0.073 | 1 | eval |
| 0.059 | 2 | train |
| 0.055 | 2 | eval |
| 0.048 | 3 | train |
| 0.045 | 3 | eval |
| 0.042 | 4 | train |
| 0.045 | 4 | eval |
| 0.039 | 5 | train |
| 0.064 | 5 | eval |
| 0.037 | 6 | train |
| 0.043 | 6 | eval |
| 0.035 | 7 | train |
| 0.040 | 7 | eval |
| 0.034 | 8 | train |
| 0.037 | 8 | eval |
| 0.032 | 9 | train |
| 0.050 | 9 | eval |
| 0.033 | 10 | train |
| 0.036 | 10 | eval |
| 0.031 | 11 | train |
| 0.032 | 11 | eval |
| 0.030 | 12 | train |
| 0.031 | 12 | eval |
| 0.030 | 13 | train |
| 0.030 | 13 | eval |
| 0.029 | 14 | train |
| 0.030 | 14 | eval |
| 0.029 | 15 | train |
| 0.030 | 15 | eval |
| 0.028 | 16 | train |
| 0.028 | 16 | eval |
| 0.028 | 17 | train |
| 0.030 | 17 | eval |
| 0.028 | 18 | train |
| 0.028 | 18 | eval |
| 0.028 | 19 | train |
| 0.029 | 19 | eval |
| 0.028 | 20 | train |
| 0.028 | 20 | eval |
| 0.027 | 21 | train |
| 0.027 | 21 | eval |
| 0.027 | 22 | train |
| 0.027 | 22 | eval |
| 0.027 | 23 | train |
| 0.027 | 23 | eval |
| 0.027 | 24 | train |
| 0.028 | 24 | eval |
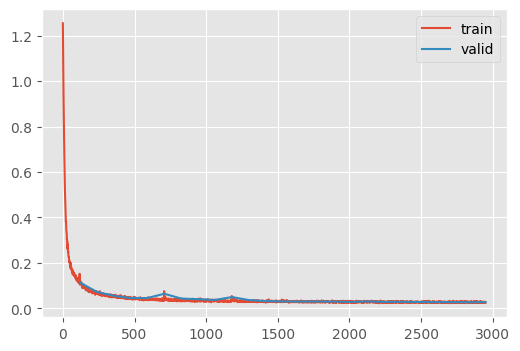
CPU times: user 16min 3s, sys: 2min 6s, total: 18min 9s
Wall time: 18min 16sx_0, _ = ddpm(un, (8, 1, 32, 32), n_steps=100)
show_images(x_0, imsize=0.8)100%|██████████████████████████████████████████████████████████| 249/249 [00:01<00:00, 130.57time step/s]
del unAdding conditionality
ConditionalTAUnet
def ConditionalTAUnet(
n_classes, nfs:tuple=(224, 448, 672, 896), attention_heads:tuple=(0, 8, 8, 8), n_blocks:tuple=(3, 2, 2, 1, 1),
color_channels:int=3
):
U-net with attention up/down-blocks
ConditionalFashionDDPM
def ConditionalFashionDDPM(
args:VAR_POSITIONAL, kwargs:VAR_KEYWORD
):
Training specific behaviors for the Learner
conditional_train
def conditional_train(
model, dls, lr:float=0.004, n_epochs:int=25, extra_cbs:list=[], loss_fn:function=mse_loss
):
un = conditional_train(
ConditionalTAUnet(
n_classes=10,
color_channels=1,
nfs=(32, 64, 128, 256, 384),
n_blocks=(3, 2, 1, 1, 1, 1),
attention_heads=(0, 8, 8, 8, 8, 8),
),
dls,
lr=4e-3,
n_epochs=25,
)| loss | epoch | train |
|---|---|---|
| 0.158 | 0 | train |
| 0.087 | 0 | eval |
| 0.058 | 1 | train |
| 0.056 | 1 | eval |
| 0.045 | 2 | train |
| 0.054 | 2 | eval |
| 0.039 | 3 | train |
| 0.042 | 3 | eval |
| 0.036 | 4 | train |
| 0.050 | 4 | eval |
| 0.034 | 5 | train |
| 0.043 | 5 | eval |
| 0.033 | 6 | train |
| 0.035 | 6 | eval |
| 0.031 | 7 | train |
| 0.039 | 7 | eval |
| 0.030 | 8 | train |
| 0.035 | 8 | eval |
| 0.030 | 9 | train |
| 0.050 | 9 | eval |
| 0.030 | 10 | train |
| 0.039 | 10 | eval |
| 0.028 | 11 | train |
| 0.035 | 11 | eval |
| 0.028 | 12 | train |
| 0.029 | 12 | eval |
| 0.028 | 13 | train |
| 0.029 | 13 | eval |
| 0.027 | 14 | train |
| 0.028 | 14 | eval |
| 0.027 | 15 | train |
| 0.027 | 15 | eval |
| 0.026 | 16 | train |
| 0.027 | 16 | eval |
| 0.026 | 17 | train |
| 0.026 | 17 | eval |
| 0.026 | 18 | train |
| 0.026 | 18 | eval |
| 0.026 | 19 | train |
| 0.026 | 19 | eval |
| 0.026 | 20 | train |
| 0.026 | 20 | eval |
| 0.025 | 21 | train |
| 0.026 | 21 | eval |
| 0.025 | 22 | train |
| 0.026 | 22 | eval |
| 0.025 | 23 | train |
| 0.026 | 23 | eval |
| 0.025 | 24 | train |
| 0.025 | 24 | eval |
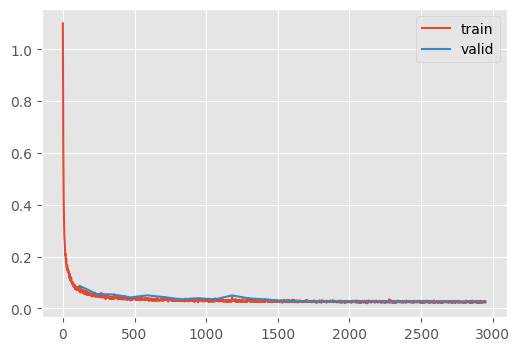
CPU times: user 16min 1s, sys: 2min 6s, total: 18min 8s
Wall time: 18min 16sconditional_ddpm
def conditional_ddpm(
model, c, sz:tuple=(16, 1, 32, 32), device:str='cpu', n_steps:int=100
):
c = torch.arange(0, 9)
x_0, _ = conditional_ddpm(un, c, (9, 1, 32, 32))
show_images(x_0, imsize=0.8);100%|████████████████████████████████████████████████████████████| 99/99 [00:00<00:00, 119.07time step/s]
x_0, _ = conditional_ddpm(un, c, (9, 1, 32, 32))
show_images(x_0, imsize=0.8);100%|████████████████████████████████████████████████████████████| 99/99 [00:00<00:00, 131.05time step/s]