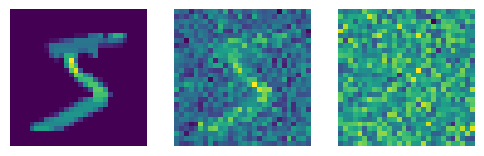
Say we want to generate images. Ideally, we would have a probability distribution of the pixels, \(P\). Let’s say that the probability distribution is for each \(28^2\) pixels. Note tha teach pixel is variables of the probability density function, or PDF for short).
We don’t have this, but say we had the derivative of this PDF. Recall that mutlivariate calculus is concerned with partial derivatives. For example, the partial derivatives of \(f(x,y)=x^2 + y^2\) are:
Found cached dataset mnist (/Users/jeremiahfisher/.cache/huggingface/datasets/mnist/mnist/1.0.0/9d494b7f466d6931c64fb39d58bb1249a4d85c9eb9865d9bc20960b999e2a332)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 104.60it/s]
An algorithm could look something like this:
For all pixel values \(X_{i,j} \in X\), evaluate the partial derivative \(\frac{P(X)-P(X + \partial X_{i,j})}{\partial X_{i,j}}\) or \(\frac{\partial P(X)}{\partial X_{i,j}}\). This can also be expressed as \(\nabla_X P\)
For some hyperparameter constant \(C\) and for all pixel values \(X_{i,j} \in X\), \(X_{i,j} := X_{i,j} + C \frac{\partial P(X)}{\partial X_{i,j}}\) or, equivalently, \(X := X + C \cdot \nabla_X P\)
Repeat until satisfied
In PyTorch, this would look something like:
X = get_image()# Somewhat unusually, you would incorporate the image as a model# parameter in order to get auto-differentiationmodel = get_nabla_X_of_P_model(X=X)for _ inrange(n_timesteps): p_grad = model.forward(X) p_grad.backward() model.X += C * model.X.grad
In fact, we don’t have \(P(X)\) or \(\nabla_X P(X)\) in real life. But we can solve a related problem.
Notice that \(\nabla_X P(X)\) provides a direction from blurrier to sharper images. We can train a neural network to de-blur by adding the blur ourselves. The input-output pair would be \(\langle image + \epsilon, \epsilon \rangle\) where \(\epsilon \sim \mathcal{N}(0, \Sigma)\) and \(\Sigma \in \mathbb{R}^{28^2 \times 28^2}\)
An aside, the mathematics
In mathematical parlance, we seek to fit a set of reverse Markov transitions to maximize the likelihood of the model on the training data. Or “minimizing the variational upper bound on the negative log likelihood.” Not sure what that mean exactly, but I’ll be targetting the mathematical level of myself 6 months ago.
First, we define some terms:
\(X^{(0)}\) is the input data distribution; for example, MNIST digits
\(Q\) and \(P\) are probability density functions
\(\beta_t\) is the “noise value” at time t
We can look to physics for inspiration in AI. This paper draws from the thermodynamics to imagine the opposite of a diffusion process: that is, evolving for a high-entropy distribution (like a noisy image) to a clear one.
In the diffusion process, we have a “forward” Gaussian Markov process called \(Q\) that governs the transition to a noisier distribution. In nature, this is a Guassian distribution: \[
Q(X^{(t)} | X^{(t-1)}) = \mathcal{N}(X^{(t-1)}\sqrt{1-\beta_t}, I\beta_t)
\] Note that at \(t=0\), we haven’t added any noise and \(B_0=0\). In fact, there is a simple expected value:
Furthermore, note that adding noise is a simple process and we generally work with the “analytic” conditional distribution where we all the noise all at once. We’ll go over this function later.
The important process to consider, however, is the “backward” Guassian Markov process called \(P\)
We want a function that maximizes the log-likelihood of this probability distribution on the data. Mathematically, this would involve the integral over the parameters and likelihood. This is mathematically intractable.
(An aside, we use log-likelihood instead of likelihood because it increases monotonically and sums are more numerically stable on computers than products.)
Instead of solving the integral directly, we use the Evidence Lower Bound. This is a score function of the model that balances maximizing the likelihood of the data under the model with the complexity of the model. \[
ELBO = E\left[log(P_\theta(X))\right] - KL(q(\theta) || p(\theta))
\] The expectation maximization term calculates the probability of the data using the PDF \(P\). The likelier the data under the model, the lower the loss. Simple.
In general, KL divergence measures the difference between distributions. In our case, it is a loss that should be minimized between the expected (or “variational”) weight distribution (\(p\)) and the actual (“true posterior”) distribution (\(q\)) of the model weights themselves. Basically, we want to see the same distributions in the reverse process that we would see in the forward process.
The \(||\) is a notation for the computation: \[
KL(q || p) = \int q(\theta)log\left( \frac{q(\theta)}{{p(\theta)}} \right) d\theta
\] Let’s break this down.
The log ratio of the point values of \(p\) and \(q\) at \(\theta\) is a measure of the difference at that point
If the probability distributions give the same likelihood for \(\theta\), the resulting value is 0
As \(q(\theta)\) goes 0 and \(p(\theta)\) goes to 1, the limit of the resulting value diverges to negative infinity
As \(q(\theta)\) goes 1 and \(p(\theta)\) goes to 0, the limit diverges to positive infinity
\(q(\theta)\) is a weight for the integrand
So, in sum, the KL diverenge is a sum of the difference in probability weighted by the probability values of the variational distribution. If the distributions are similar, the KL divergence is small; otherwise, they are large.
Interestingly, Ho et al fixes the variance schedule. In turns out, this makes it so that the covariance matrix is constant, the KL divergence term goes to 0 and we only need to estimate the mean.
We can train a model to do so with MSE loss.
This course will demonstrate how to do so from scratch.
Let’s begin by running the algorithm.
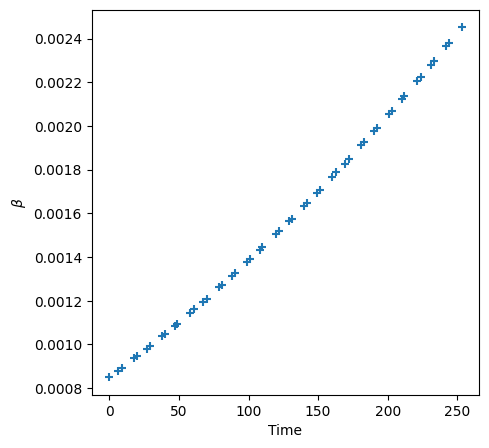
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")# Use a simple noising scheduler for the initial draftpipe.scheduler = LMSDiscreteScheduler( beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000,)pipe = pipe.to(TORCH_DEVICE)pipe.enable_attention_slicing()prompt ="a photo of a giraffe in Paris"pipe(prompt).images[0]
Now that we see what Stable Diffusion is capable of, we note its three components:
Variational Autoencoder
CLIP
Unet
Model components
Variational Autoencoder
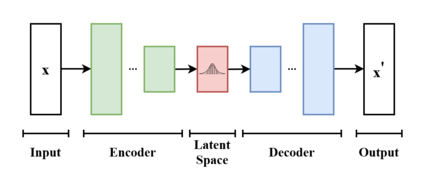
Stable Diffusion is a latent diffusion model. That means that the model manipulates vectors within the latent space manifold of another model. In this case, that model is a Variational Autoencoder.
vae = pipe.vae
Variational autoencoders are trained to compress vector information into a normal distribution manifold and decompress it with minimal reconstruction loss.
image.png
We can visualize the information from a trained VAE.
We’ll get much more into the architecture of the U-net later. For now, know that it is a model with a strong translational equivariance property.
There are two inputs to the model: the prompt and the time.
The time is an index of how noisy the image is. This helps the model to determine how much noise to remove, because the amount of noise added at any given step is non-linear.
The other thing we could add to make the problem of de-noising easier is to indicate the image class (1, 2, 3, etc). For a simple class distribution, we could just one hot-encode it. The input-output pair would then be \(\langle \left( image + \epsilon, t, class \right), \epsilon \rangle\).
But we cannot one-hot encode the distribution of images on the internet à la Stable Diffusion. Therefore, we need a more sophisticated encoder: CLIP (Constrastively Learned Image Pairs). This works on the idea that the dot-product between image encoding and text encoding of the same thing should be large, while the image encoding and text encoding for different things should be small.
We learn this with a neural network contrastively. For a given batch, \(B\), of (image, language) pairs from html alt tags:
Compute the encoding \(f_{image}(I_i)\) and \(f_{language}(L_i)\) for all \(i \in |B|\)
Compute the sum \(\text{correctly paried loss} := \Sigma_i^{|B|} f_{image}(I_i) \cdot f_{language}(L_i)\)
Final loss = incorrectly paired loss - correctly paired loss. Note that want the overall loss to be small or negative, so we take the negative of the sum of the correctly paired dot products. This pushes the vectors for correctly paired language image to be in the same subspace, and incorrectly paired counterparts into different subspaces.
with torch.no_grad(): text_embeddings = text_encoder(tokens.to(TORCH_DEVICE)).last_hidden_statetext_embeddings.shape
torch.Size([1, 9, 768])
In fact, this isn’t used to directly denoise the image during inference. We use a hack called Classifier Free Guidance (CFG), where – in addition to the latents – the model is prompted with a null prompt (an unconditional prompt) and and the original prompt.
See more here: https://www.youtube.com/watch?v=344w5h24-h8
Putting it together
With these components in mind, we can start to put them together.
There are many ways to sample from Stable Diffusion. The original sampling was a simple numerical differential equation solver (known as the linear multistep solver or LMS): where we take the steps that the gradient suggests with the magnitude of the solver.
It should be noted that this is similar to solving for neural network weights. Therefore, we take a step accourding to the optimizer and wait for convergence.
We can also use the tricks associated with successful neural network training. It is well-understood that the derivative isn’t always a good indicator of the loss curvature. We can improve the quality of the right direction by incorporating previous computations of the gradient (i.e., momentum).
Read more about that here: https://stable-diffusion-art.com/samplers/
Hacking
Optimizing pixels directly
We are not constrained to using the algorithms as presented to us. This is all just calculus, so we can optimize with respect to arbirary loss functions.
@dataclassclass StableDiffusionWithArbitraryLoss(StableDiffusion): loss_f: Callable k: float periodicity: int=5def denoise(self, prompt_embedding, l, t, guidance_scale, i):if i %self.periodicity ==0and i !=0:# Calculate noise as per usual noise_pred =self.pred_noise(prompt_embedding, l, t, guidance_scale)# Create a copy of the latents that keeps track of the gradients l = l.detach().requires_grad_()# Take a step all the way towards a predicted x0 and use this to# compute the loss l_x0 =self.scheduler.step(noise_pred, t, l).pred_original_sample image_x0 = decompress(l_x0, self.vae, as_pil=False, no_grad=False) loss =self.loss_f(image_x0) *self.kprint(f"{i}: arbritrary loss: {loss}")# Compute the loss gradient with respect to the latents and take# a step in that direction (grad,) = torch.autograd.grad(loss, l) sigma =self.scheduler.sigmas[i] l = l.detach() - grad * sigma**2else:with torch.no_grad(): noise_pred =self.pred_noise(prompt_embedding, l, t, guidance_scale) l =self.scheduler.step(noise_pred, t, l).prev_samplereturn ldef blue_loss(images):return torch.abs(images[:, 2] -0.9).mean()StableDiffusionWithArbitraryLoss( tokenizer=tokenizer, text_encoder=text_encoder, scheduler=scheduler, unet=unet, vae=vae, loss_f=blue_loss, k=75, periodicity=5,)("a photo of an octopus, national geographic, dlsr", n_inference_steps=30, as_pil=True,)
/Users/jeremiahfisher/miniforge3/envs/slowai/lib/python3.9/site-packages/torch/autograd/__init__.py:303: UserWarning: The operator 'aten::sgn.out' is not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/mps/MPSFallback.mm:11.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
33%|███████████████████████████████████████████████▋ | 10/30 [00:40<01:21, 4.09s/it]
Look! Less blue than you would expect for an underwater scene. Cool 😎
Tinkering with the prompt embedding
We are also not constrained to the text embeddings directly from CLIP. We can take embeddings from different tokens and hack them apart.
prompt ="an adorable photo of a puppy"tokens_a = tokenizer(prompt, return_tensors="pt").input_idsfor t in tokens_a[0, ...]:print(f"{t}: {tokenizer.decoder.get(int(t))}")text_embeddings_a = text_encoder(tokens_a.to(TORCH_DEVICE)).last_hidden_statetext_embeddings_a.shape
prompt ="a adorable photo of a koala"tokens_b = tokenizer(prompt, return_tensors="pt").input_idsfor t in tokens_b[0, ...]:print(f"{t}: {tokenizer.decoder.get(int(t))}")with torch.no_grad(): text_embeddings_b = text_encoder(tokens_b.to(TORCH_DEVICE)).last_hidden_statetext_embeddings_b.shape