Modules will be added to it in the order they are passed in the constructor. Alternatively, an OrderedDict of modules can be passed in. The forward() method of Sequential accepts any input and forwards it to the first module it contains. It then “chains” outputs to inputs sequentially for each subsequent module, finally returning the output of the last module.
The value a Sequential provides over manually calling a sequence of modules is that it allows treating the whole container as a single module, such that performing a transformation on the Sequential applies to each of the modules it stores (which are each a registered submodule of the Sequential).
What’s the difference between a Sequential and a :class:torch.nn.ModuleList? A ModuleList is exactly what it sounds like–a list for storing Module s! On the other hand, the layers in a Sequential are connected in a cascading way.
Example::
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1, 20, 5), nn.ReLU(), nn.Conv2d(20, 64, 5), nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(
OrderedDict(
[
("conv1", nn.Conv2d(1, 20, 5)),
("relu1", nn.ReLU()),
("conv2", nn.Conv2d(20, 64, 5)),
("relu2", nn.ReLU()),
]
)
)
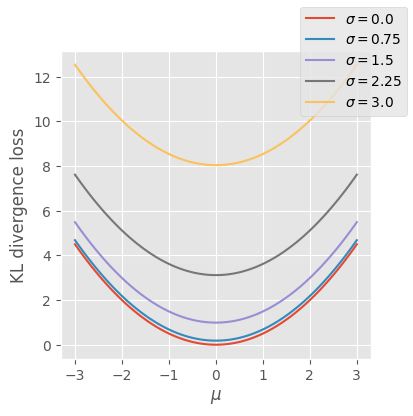
Sigma can go to 0 to preserve data in the activations, so we need a new loss function to make sure that the hidden distribution is normal. This is known as “Kullback–Leibler divergence” or “KLD” loss. This reaches a minimum when μ is 0 and σ is 1.
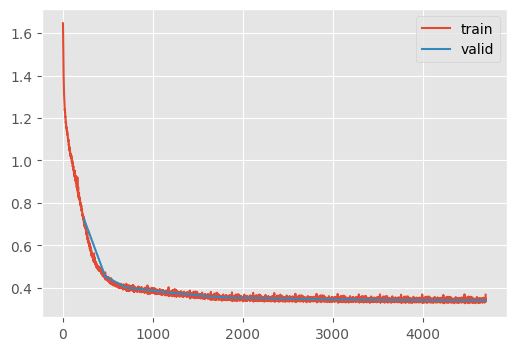
We want to be able to keep track of the KLD loss over time, so let’s track it in a metric.
MeanlikeMetric
def MeanlikeMetric( kwargs:VAR_KEYWORD):
Base class for all metrics present in the Metrics API.
This class is inherited by all metrics and implements the following functionality:
1. Handles the transfer of metric states to the correct device.
2. Handles the synchronization of metric states across processes.
3. Provides properties and methods to control the overall behavior of the metric and its states.
The three core methods of the base class are: add_state(), forward() and reset() which should almost never be overwritten by child classes. Instead, the following methods should be overwritten update() and compute().
Args: kwargs: additional keyword arguments, see :ref:Metric kwargs for more info.
- **compute_on_cpu**:
If metric state should be stored on CPU during computations. Only works for list states.
- **dist_sync_on_step**:
If metric state should synchronize on ``forward()``. Default is ``False``.
- **process_group**:
The process group on which the synchronization is called. Default is the world.
- **dist_sync_fn**:
Function that performs the allgather option on the metric state. Default is a custom
implementation that calls ``torch.distributed.all_gather`` internally.
- **distributed_available_fn**:
Function that checks if the distributed backend is available. Defaults to a
check of ``torch.distributed.is_available()`` and ``torch.distributed.is_initialized()``.
- **sync_on_compute**:
If metric state should synchronize when ``compute`` is called. Default is ``True``.
- **compute_with_cache**:
If results from ``compute`` should be cached. Default is ``True``.
KLDMetric
def KLDMetric( kwargs:VAR_KEYWORD):
Base class for all metrics present in the Metrics API.
This class is inherited by all metrics and implements the following functionality:
1. Handles the transfer of metric states to the correct device.
2. Handles the synchronization of metric states across processes.
3. Provides properties and methods to control the overall behavior of the metric and its states.
The three core methods of the base class are: add_state(), forward() and reset() which should almost never be overwritten by child classes. Instead, the following methods should be overwritten update() and compute().
Args: kwargs: additional keyword arguments, see :ref:Metric kwargs for more info.
- **compute_on_cpu**:
If metric state should be stored on CPU during computations. Only works for list states.
- **dist_sync_on_step**:
If metric state should synchronize on ``forward()``. Default is ``False``.
- **process_group**:
The process group on which the synchronization is called. Default is the world.
- **dist_sync_fn**:
Function that performs the allgather option on the metric state. Default is a custom
implementation that calls ``torch.distributed.all_gather`` internally.
- **distributed_available_fn**:
Function that checks if the distributed backend is available. Defaults to a
check of ``torch.distributed.is_available()`` and ``torch.distributed.is_initialized()``.
- **sync_on_compute**:
If metric state should synchronize when ``compute`` is called. Default is ``True``.
- **compute_with_cache**:
If results from ``compute`` should be cached. Default is ``True``.
BCEMetric
def BCEMetric( kwargs:VAR_KEYWORD):
Base class for all metrics present in the Metrics API.
This class is inherited by all metrics and implements the following functionality:
1. Handles the transfer of metric states to the correct device.
2. Handles the synchronization of metric states across processes.
3. Provides properties and methods to control the overall behavior of the metric and its states.
The three core methods of the base class are: add_state(), forward() and reset() which should almost never be overwritten by child classes. Instead, the following methods should be overwritten update() and compute().
Args: kwargs: additional keyword arguments, see :ref:Metric kwargs for more info.
- **compute_on_cpu**:
If metric state should be stored on CPU during computations. Only works for list states.
- **dist_sync_on_step**:
If metric state should synchronize on ``forward()``. Default is ``False``.
- **process_group**:
The process group on which the synchronization is called. Default is the world.
- **dist_sync_fn**:
Function that performs the allgather option on the metric state. Default is a custom
implementation that calls ``torch.distributed.all_gather`` internally.
- **distributed_available_fn**:
Function that checks if the distributed backend is available. Defaults to a
check of ``torch.distributed.is_available()`` and ``torch.distributed.is_initialized()``.
- **sync_on_compute**:
If metric state should synchronize when ``compute`` is called. Default is ``True``.
- **compute_with_cache**:
If results from ``compute`` should be cached. Default is ``True``.
It took quite a bit of work to ensure that these results matched Howards’:
Use SiLU instead of ReLU
Initialize leakily
Normalize the output before visualizing
Ensure there were the number of encoder layers as decoder layers
Use the original FashionMNIST, not the one upsampled to 32x32 for DDPM.
with torch.no_grad(): xb = rearrange(x, "b c h w -> b (c h w)") xb_pred, _, _ = to_cpu(vae(xb.cuda()))xb_pred = rearrange(xb_pred.sigmoid(), "b (c h w) -> b c h w", c=1, h=28, w=28)xb_pred = xb_pred.float()